Efficient data transfer through zero copy
Zero-copy I/O practice in project
Recently weeks, I was working on how to exploit the potentialities with the GMAC(1G Ethernet Media Access Controller) on the SoC in my desktop. This SoC was used in the telecommunication field which provide the fast-transfer-data capability with some interesting MAC features. In this article, I had like share some experiences on how to utilize this MAC achieving better network throughput during this work.
Preface
@[Blog] The following articles were worth having a look before going forward.
- Zero Copy I: User-Mode Perspective (from Linux Journal, strongly recommended to read)
- An Efficient Zero-Copy I/O Framework for UNIX (most of thoughts comes from here)
After reading these articles, then you will know how the Java.nio.channels works. If you have more time, you can dig more on the Kafaka, the most popular message queue framework written by LinkedIn.
So, let’s first look at the capability of PHY/MAC in my hand.
The PHY was provided by Atheros AR8031 as Ethernet transceiver and Atheros AR8327 as Ethernet switch.
- Compatible with IEEE Standard 802.3.
- Full duplex operation 1000 Mbps operation speeds.
- Statistics counter registers for RMON/MIB.
- Embedded DMA.
- Only for SGMII: Integrated Physical Coding Sub-layer (PCS) with auto-negotiation.
- MDIO interface provided to control external phys from the Embedded RISC processor.
- Automatic pad and cyclic redundancy check (CRC) generation on transmitted frames.
- Automatic discard of frames received with errors.
- Receive and transmit IP, TCP and UDP checksum offload. Both IPv4 and IPv6 packet types supported.
- Address checking logic for four specific 48-bit addresses, four types of Ids, promiscuous mode, external address checking, hash matching for unicast and multicast destination addresses and Wake-on-LAN.
- Programmable IPG stretch.
- Support for 802.1Q VLAN tagging with recognition of incoming VLAN and priority tagged frames.
- Support for 802.1Qbb priority-based flow control – PFC Negotiation mode.
- Full utilization of the Tx 1 Gbps line.
- Provides sufficient buffer 16KB to support lossless reception of maximum length (jumbo-type) up to 10,240Bytes Ethernet frames.
- For RGMII only: RGMII electrical characteristics compliant with RGMII v1.3 (thus based upon 2.5V CMOS interface voltages as defined by JEDEC EIA/JESD8-5), and are not compliant with RGMII v2.0.
- Support for 1588 V1/V2.
- Support for 802.3az Energy Efficient Ethernet
Some advanced features which attract on me were:
- Statistics counter registers for RMON/MIB. (then we can get performance comparison on the MAC level, great feature.)
- Programmable IPG stretch.
- Checksum offload.
- Automatic padding and CRC generation.
- 10KB buffer!
- Sctter-Gather capability!
Do it
In this embedded project, it was not allowed 3rd organization/person install/uninstall any package without authorization, which was guaranteed by the Trust Zone Area, it means any installed package after HASH self-signed must be verified by the public key install on this area, otherwise it will failed to get install or upgrade.
What I want to said was - we trust the software installed on the board. Then it means we don’t need to consider the security issues mentioned in the 2nd article. Then we can simplify our design without considering security.
Some highlight feature include:
- Direct linear address mapping (vir2phy, phy2vir). support more than one page size space.
- Zero-copy from filling the message in user space to sending message into the device in kernel space. (This GMAC support scatter-gather functionality , and the kernel later than 2.6.xx support the scatter-gather functionality)
- Public API to application in user space, another public API to device driver in kernel module.
- It provide a simple memory cache scheme in user space level, decreasing the system trap call on most circumstances. as well as it will re-fill/request to the memory pool if the threshold reached, one system call was happened only till this time.
- It expose more detailed real-time information in /proc file-system.
Some aspects need to consider in front of project are:
- Memory access time is unpredictable.
- Memory bandwidth is limited.
- Data change between application is very high.
- Lifetime of exchanging data was short. (get/put)
- Linux use page table translation to get better protection, which means it was not so straightforward to access memory.
- Other hardware limitation, (System BUS bandwidth, MAC interface).
These limitations/requirements decide the way what we do.
In purpose of better memory management between kernel space and user space, we setup a raw virtual device with fixed I/O start address and length when start kernel, then both user space application which can use mmap() mapping the I/O space to its own virtual address and kernel module can access the same memory address via the fixed offset.
There are some inherent access attributes on those memory, so it is necessary to have a test on which cache scheme was best suit for our requirement.
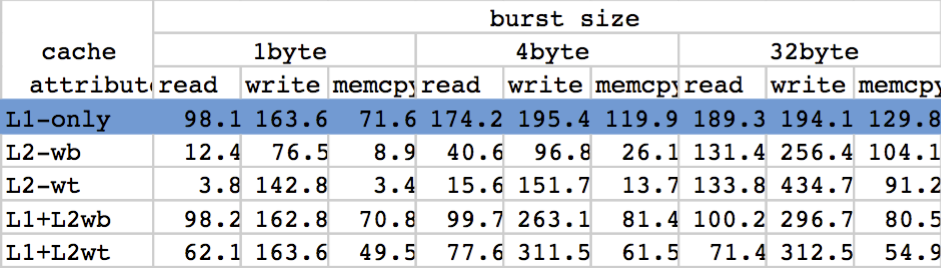
For achieve the best system efficiency:
- Use L1-only cached memory.
- Zero-copy whenever possible.
- Minimize number of system calls and context switch.
So, let’s have a look at this picture show:
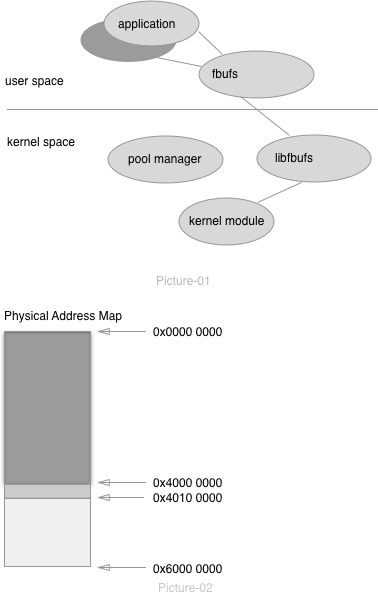
Design details
End
Actually, in our products, other module/process also use this POOL as hot-fast data storage, such like we develop the fsyslog which was an log framework providing the functions like syslogd(…) in Unix but it provide shared-memory based logging scheme with faster and non-blocking operation when logging in user application, etc.
Later I will show the comparison after this changes, which achieving more than 30% throughput boost in whole and 2% load decrease in our specified product.